Chose relativement rare, j’ai eu l’opportunité de travailler sur la version On-Premise de SQL Data Warehouse, APS (Analytics Platform System). Il s’agit d’une appliance dédiée aux entrepôts de données décisionnels, à l’analyse Big Data, avec un système distribué pour le calcul et le stockage. Cette solution permet aussi une intégration rapide des données à partir de fichiers avec la présence de Polybase et la possibilité de les croiser avec des données relationnelles. Pour résumer, APS est le grand frère On-Premise de SQL Server mais côté Business Intelligence. Bref, je remet le couvert mais dans le cadre d’un projet Azure cette fois, avec SQL Data Warehouse, son éponyme dans le cloud en mode PaaS. Avec SQL Data Warehouse, on n’a plus qu’à se concentrer sur le chargement et l’interrogation de données, enfin presque… On le verra plus tard, la création d’un DWH ou la migration d’un existant ne vont pas de soi non plus.
Cet article aborde les sujets suivant :
Pourquoi le cloud finalement ?
Moteur MMP VS SMP
Modèles de distribution : Hachage, tourniquet, réplication
Codes, structure et capacité
SSIS, BCP et Polybase
Stockage et calcul (cDWU) facturés séparément
Rôles affectés aux logins : Smallrc, Mediumrc, largerc, xlargerc
Classes de ressource et cDWU
Informations sur les bases de données et métriques de performance
Pourquoi SQL Data Warehouse ?
Les avantages à utiliser SQL Data Warehouse ne sont pas négligeables, typiquement :
- Capacités qui s’adaptent à vos besoins (cDWU : Compute Data Warehouse Units)
- Facturation prévisible
- Arrêt possible du service et/ou réduction du niveau de service (cDWU )
- Peu de maintenance
- Produit en constante évolution
- Sortie d’un job Stream Analytics
Si vous avez encore des interrogations sur la pertinence de ce service dans Azure, n’hésitez pas à parcourir cet arbre de décision communiqué par Charles-Henri Sauget.
Architecture

Une différence notable entre SQL Data Warehouse et un SQL Server classique, c’est que le premier a un moteur MPP (Massively Parallel Processing) autrement dit « Traitement Massivement Parallèle » avec une distribution du calcul et du stockage sur plusieurs nœuds. Alors que le second utilise le mode SMP (Symmetric Multiprocessing), donc avec des charges de travail s’exécutant sur une machine physique ou VM unique. Avec un moteur MPP, les requêtes s’exécutent en moyenne 50 fois plus vite sur SQL Data Warehouse, que les entrepôts de données standard reposant sur des systèmes de gestion de base de données SMP.

Le moteur MPP est le cerveau du système de traitement massivement parallèle (MPP). Il effectue les opérations suivantes :
- Création des plans de requête parallèles et coordination de l’exécution sur les nœuds de calcul
- Stockage des éléments de configuration et de métadonnées de toutes les bases de données
- Gestion des autorisations et authentifications
- Suivi d’état matériel et logiciel
Dans cette architecture, il faut distinguer deux types de nœuds :
- Nœud de contrôle : Il s’agit du point d’entrée, il reçoit toutes les connexions et orchestre l’exécution des requêtes. La requête est optimisée puis adressée aux nœuds de calcul pour son exécution en mode parallèle. Il n’y a qu’un nœud de contrôle.
- Nœuds de calcul : Un nœud de calcul constitue une unité de stockage (en attachement direct) et de traitement parallèle des données. SQL Data Warehouse repose sur une architecture permettant de répartir les charges de travail entre plusieurs nœuds de calculs.
Une autre service interne à prendre en compte, est le DMS (Data Movement Service), il est en charge du déplacement de données entre les nœuds de calculs pour la résolution d’une requête. Ce service sera plus ou moins sollicité suivant la distribution des données et les requêtes effectuées, à suivre.
Distribution
Autre pierre angulaire du système, il faut compter sur un répartition de table qui propose plusieurs modèles de distribution :
- Hachage : Une fonction de hash détermine la distribution des données sur les nœuds de calcul.
- Tourniquet : Les données réparties équitablement entre les nœuds de calcul, à tour de rôle.
- Réplication: Chaque nœud de calcul dispose d’une copie des données.
Nous disposons de 60 buckets pour la distribution d’une table. La distribution d’une table est transparente, elle apparaît sous la forme d’une entité unique, mais les lignes sont en réalité stockées sur 60 distributions. Les lignes peuvent être distribuées avec un algorithme de hachage ou de tourniquet.
Pour choix d’une distribution, vous pouvez vous référer à cet article : Distribution des tables sur SQL Data Warehouse.
Limitations
Cela étant, bien qu’Azure ait une version d’avance par rapport à la solution On-premise, je retrouve un certain nombre de limitations, tant au point de vue de la capacité, du code et de la structure. En terme de capacité, il y a deux chiffres à retenir :
- Nombre de sessions concurrentes : 1024 (VS 32767 sur un SQL Server classique)
- Nombre de requêtes concurrentes : 128 (VS 32 pour SQL Data Warehouse en génération 1)
|
1 2 |
-- Nombre de connexions simultanées maximum sur une instance SQL Server SELECT @@MAX_CONNECTIONS AS MaxConnections; |
Pour la migration ou création d’une base de données à héberger sur SQL Data Warehouse, prêtez une attention particulière au guide de MS.
Tables
Typiquement concernant les tables, voici une liste non exhaustive de ce qui n’est pas supporté :
- Pas de contraintes de table : Primary Key, Foreign Key, Unique et Check
- Pas de colonnes calculées
- Pas de vue indexées
- Pas d’index unique
Types de données
Concernant les types de données, certains sont limités en taille ou d’autres non supportés dans le pire des cas :
- VARCHAR(MAX) & NVARCHAR(MAX) limité à 8000 : ce qui peut être impactant pour l’exécution de code T-SQL dynamique
- GEOGRAPHY
- GEOMETRY
- XML
Procédures stockées
Idem pour les procédures stockées, vous devrez là encore faire quelques compromis :
- 8 niveaux d’imbrication (VS 32 pour un SQL Server classique)
- Résultat d’une PS non injectable dans une table via la méthode INSERT..EXECUTE
Variables et tables temporaires
L‘initialisation de variables et la gestion des tables temporaires présentent aussi quelques variantes.
Code
Au niveau du code, il faudra aussi faire quelques adaptations pour remplacer certaines instructions telles que :
- MERGE
- Requêtes d’UPDATE et DELETE avec jointure
- CTE : pour la création d’une dimension Temps : passez par une table stockée dans un moteur classique de SQL Server ou utilisez une boucle WHILE
Statistiques
Contrairement à SQL Server, qui crée et/ou met à jour les statistiques automatiquement, SQL Data Warehouse nécessite une tenue manuelle des statistiques.
Data Warehouse Migration Utility
N’espérez pas migrer une base existante en un clic. Pas de panique, il existe un outil en preview qui permet d’évaluer la compatibilité et de migrer dans un second temps : Data Warehouse Migration Utility. La compatibilité va être évaluée sur la base de règles définies sur deux axes, le code et les objets, avec un niveau de sévérité et un nombre d’occurrences. Voici un exemple de rapport à l’issu du test de comptabilité :

Les noms d’objets non éligibles à une migration ne sont pas indiqués, dommage…
La création des tables avec Data Warehouse Migration Utility, vous laisse le choix de la distribution (tourniquet ou hachage, + colonne de hash, % de données).
Quand à la migration de données, elle peut se faire par SSIS ou BCP.
Il n’y actuellement pas de prise en charge de SQL Data Warehouse dans un projet de base de données mais c’est une évolution à venir.

Chargement de données
Le chargement de données peut être réalisé de plusieurs manières :
- BCP et SSIS : l’inconvénient de ces méthodes réside dans le fait qu’elles passent par le nœud de contrôle, ce qui constitue un goulot d’étranglement.
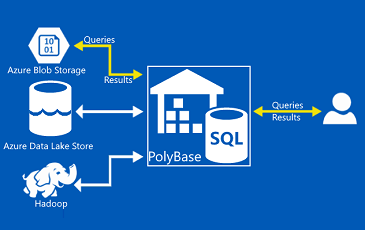
- Polybase : Pour cette méthode, on passe directement par les nœuds de calcul. Cette méthode est recommandée avec quelques précautions : privilégier peu de gros fichiers (VS beaucoup de petits fichiers), et non compressés pour bénéficier du parallélisme (multi-thread).
Coût
Pour SQL Data Warehouse, le stockage est facturé séparément du calcul. Le stockage est facturé à la quantité par incrément de 1To, en Standard ou Premium Geo Redondant. Le calcul est quand à lui facturé par cDWU (compute Data Warehouse Units) allant de 100 à 30 000 par heure.
cDWU, kezako ? Cela représente une mesure abstraite et standardisée des ressources de calcul et de performances entre consommation CPU, mémoire, I/O sur une base de données. Sur un SQL Data Warehouse de génération 2, supposé être 5 fois plus rapide grâce à un système de cache, le niveau de service est mesuré en cDWU (compute Data Warehouse Unit), par exemple DW2000C. Prenons un exemple pour le choix de cDWU : il y aura approximativement un gain x5 sur un DW500c, comparativement à un DW100c que ce soit en temps de chargement d’une table ou temps d’exécution pour l’affichage d’un rapport.
Le choix d’un cDWU affecte bien évidemment la performance, en déterminant :
- Le nombre de nœuds de calcul
- La mémoire par nœuds de calcul
- La concurrence
Pour connaître le niveau de service d’une base de données en cDWU, exécutez la requête suivante :
|
1 2 3 |
SELECT * FROM sys.database_service_objectives ds INNER JOIN sys.databases db ON ds.database_id = db.database_id |
Comme indiqué dans les avantages de SQL Data Warehouse, le service peut être mis en pause (VS SQL Database) et ou le niveau de service dégradé en nombre de cDWU (attention : opération offline). On peut maintenir le service démarré pendant la durée des chargements de données, calculs, rapprochements et traitement de cube. Autre option, on peut aussi diminuer le niveau de service pour certaines opérations.
Le niveau de cDWU est aussi impactant pour la concurrence, soit le nombre d’exécutions de requêtes en simultané. Il existe d’autres paramètres qui influent sur cette capacité, comme la classe de ressource.
Classe de ressource
Un peu à l’image du Resource Governor sur un SQL Server classique, les classes de ressource permettent de limiter la mémoire et la concurrence pour chaque requête. Chaque connexion est membre d’une classe de ressource via un rôle et donc indirectement la ou les requêtes exécutées par celui-ci sont affectée. L’idée est de faire un compromis entre la mémoire et la concurrence :
- Des classes de ressource plus petites (smallrc, mediumrc) réduisent la mémoire maximale par requête, mais améliore la concurrence.
- Des classes de ressource plus grandes (largerc, xlargerc) augmentent la mémoire maximale par requête, mais réduisent la concurrence.
Classes de ressource (rôles) affectés aux logins :
|
1 2 3 4 5 |
SELECT r.name AS role_principal_name , m.name AS member_principal_name FROM sys.database_role_members rm INNER JOIN sys.database_principals AS r ON rm.role_principal_id = r.principal_id INNER JOIN sys.database_principals AS m ON rm.member_principal_id = m.principal_id |
La liste des opérations prises en compte par les classes de ressources sont les suivantes :
- INSERT-SELECT
- UPDATE
- DELETE
- SELECT (tables utilisateurs)
- ALTER INDEX REBUILD
- ALTER INDEX REORGANIZE
- ALTER TABLE REBUILD
- CREATE INDEX
- CREATE CLUSTERED COLUMNSTORE INDEX
- CREATE TABLE AS SELECT
- Chargement de données
- Mouvements de données (DMS)
A l’inverse, les oprétaions qui ne seront pas limités par les classes de ressources :
- SELECT (DMV)
- CREATE TABLE
- ALTER TABLE … SWITCH PARTITION
- ALTER TABLE … SPLIT PARTITION
- ALTER TABLE … MERGE PARTITION
- DROP TABLE
- ALTER INDEX DISABLE
- DROP INDEX
- CREATE STATISTICS
- UPDATE STATISTICS
- DROP STATISTICS
- TRUNCATE TABLE
- ALTER AUTHORIZATION
- CREATE LOGIN
- CREATE USER
- ALTER USER
- DROP USER
- CREATE PROCEDURE
- ALTER PROCEDURE
- DROP PROCEDURE
- CREATE VIEW
- DROP VIEW
- INSERT VALUES
- SELECT (from system views and DMVs)
- EXPLAIN
- DBCC
Contrôle de la performance
Indépendamment de la qualité du code, de la structure et de la maintenance de la base de données, il y a finalement deux leviers principaux pour améliorer la performance :
- Augmenter la classe de ressource (rôle) d’un login :
|
1 |
EXEC sp_addrolemember 'mediumrc', 'bidule' |
- Augmenter le nombre de cDWU, de manière temporaire ou permanente :
|
1 |
ALTER DATABASE DatabaseName MODIFY (SERVICE_OBJECTIVE = 'DW2000c'); |
DMV
A l’image d’un SQL Server classique, SQL Data Warehouse dispose d’un certain nombre de DMV pour obtenir des informations sur SQL Data Warehouse, les bases de données ou encore des métriques sur la distribution, les requêtes, etc.
Pour connaître le nombre de nœuds disponibles par type (nombre en fonction du niveau de services : cDWU) :
|
1 2 3 |
SELECT [type], COUNT(*) AS node_count FROM sys.dm_pdw_nodes GROUP BY [type] |
Cette requête renvoie les lignes et l’espace par table :
|
1 |
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales'); |
Cette requête renvoie la progression d’un charge de travail :
|
1 2 3 4 5 |
SELECT * FROM sys.dm_pdw_exec_requests r INNER JOIN sys.dm_pdw_dms_workers w on r.request_id = w.request_id WHERE r.[label] = 'Load [prod].[FactTransactionHistory]' ORDER BY w.start_time desc; |
Information de distribution pour une requête :
|
1 2 3 4 |
SELECT req.* FROM sys.dm_pdw_exec_requests r INNER JOIN sys.dm_pdw_sql_requests req on r.request_id = req.request_id ORDER BY req.step_index,req.distribution_id |
Attente au global :
|
1 2 3 4 5 6 7 8 |
SELECT w.[pdw_node_id] , w.[wait_name] , w.[max_wait_time] , w.[request_count] , w.[signal_time] , w.[completed_count] , w.[wait_time] FROM sys.dm_pdw_wait_stats w |
Attentes en cours sur les requêtes :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
SELECT w.[wait_id] , w.[session_id] , w.[type] AS Wait_type , w.[object_type] , w.[object_name] , w.[request_id] , w.[request_time] , w.[acquire_time] , w.[state] , w.[priority] , SESSION_ID() AS Current_session , s.[status] AS Session_status , s.[login_name] , s.[query_count] , s.[client_id] , s.[sql_spid] , r.[command] AS Request_command , r.[label] , r.[status] AS Request_status , r.[submit_time] , r.[start_time] , r.[end_compile_time] , r.[end_time] , DATEDIFF(ms,r.[submit_time],r.[start_time]) AS Request_queue_time_ms , DATEDIFF(ms,r.[start_time],r.[end_compile_time]) AS Request_compile_time_ms , DATEDIFF(ms,r.[end_compile_time],r.[end_time]) AS Request_execution_time_ms , r.[total_elapsed_time] FROM sys.dm_pdw_waits w INNER JOIN sys.dm_pdw_exec_sessions s ON w.[session_id] = s.[session_id] INNER JOIN sys.dm_pdw_exec_requests r ON w.[request_id] = r.[request_id] WHERE w.[session_id] <> SESSION_ID() |
Auteur

- Experte SQL Server Prod/Etude avec un bonus sur la BI, speaker aux SQL Saturday et Journées SQL Server et enfin formatrice Orsys, je dispose d'une vision d'ensemble des systèmes d'information, d'une appétence pour l'industrialisation et d'un souci permanent de la performance.